There is a way to reconfigure a SQL Server cluster after a P2V (Physical to Virtual) without having to reinstall SQL. I want to warn you though that the method probably wouldn't be sanctioned by the Microsoft powers and I can only recommended it to those who are comfortable with living on the edge. I will say that I've performed this process on over a dozen production clusters. They have been running without error for over 6 months. The process really was one of necessity based on having an exceedingly aggressive P2V schedule. Are there risks - certainly, but then again isn't this why we became DBA's?
First Steps
In a large organization you'll need to work closely with the team responsible for converting the server to a virtual server. If you are the DBA and you happen to also be the one responsible for the conversion then these steps still apply and you're lucky enough to not have to schedule as many meetings.
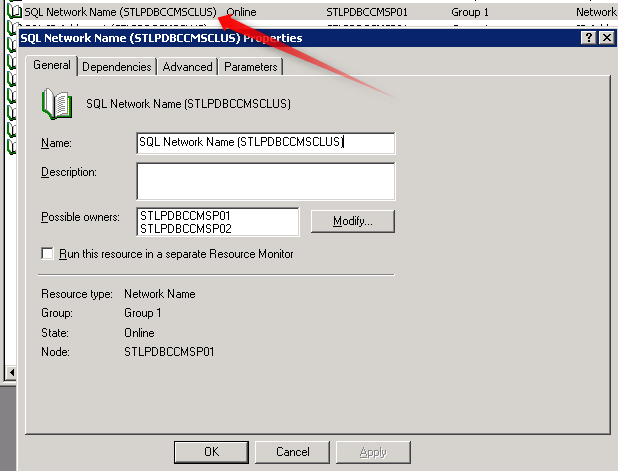
Assuming we are only dealing with a 2-node cluster your configuration consists of 2 physical node names and 2 virtual names - one for SQL and one for the server. The only name you'll want to retain post P2V is the SQL Network Name. This is the name your application(s) should be connecting to and is the same as the default instance. You could choose a different name, but you'll be causing yourself much more trouble than it's worth.
In the image below the SQL Network Name is called STLPDBCCMSCLUS and it contains nodes STLPDBCCMSP01 and STLPDBCCMSP02. Both of the physical node names will be removed after the P2V and the only name you'll use is the original SQL Network Name.
Finally, you'll need to ensure the same drive letters are used. For example, if the cluster has LUNs F and G than the new VM should also have LUNs F and G. Again, you could change this, but it wouldn't be worth the effort. What will be removed is the quorum drive, usually Q. This will cause you problems with MSDTC, but we'll discuss this later in the tip.
Now for the Tricky Part
Everything you do during this tip will need to be completed during the P2V downtime. You or another team will shutdown production and begin the conversion. Once the conversion is completed SQL will try to start but fail. This is where you come in to save the day.
The first order of business is to remove all the unused IP addresses. If you remember the cluster had 4 server names (2-nodes, SQL name, server name). It now only has one. This means there is only one IP address being used, but SQL still thinks there are many. If you had looked in the Network settings on the cluster you would have seen something similar to this:
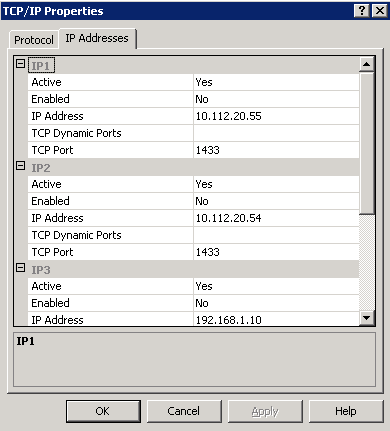
This screenshot shows 3 out of the 4 entries. There is also a loopback entry of 127.0.0.1. These TCP\IP entries simply refer to values in the registry and this is where we will make the changes. For SQL 2005 you should be able to find them at HKLM\Software\Microsoft\Microsoft SQL Server\MSSQL.1\MSSQLServer\SuperSocketNetLib. Determine the IP address of the new server and then remove all of the key entries except for the loopback entry, the server IP, and the IPAll. I make IP1 the IP address of the server and IP2 the loopback IP.
You will also see a key called "Cluster" under HKLM\Software\Microsoft\ Microsoft SQL Server\MSSQL.1\. The entire key can be deleted.
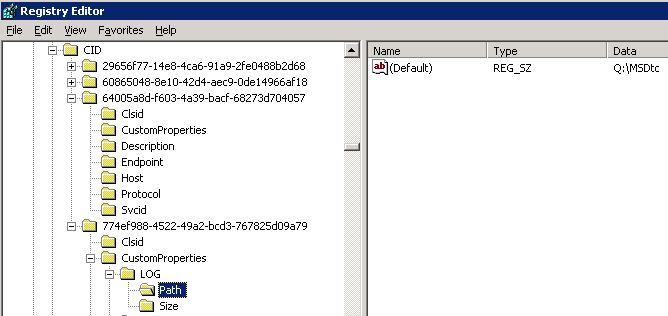
Only one more thing needs to be done before starting SQL Server. If your cluster was correctly configured than MSDTC would have a dependency on SQL Server. This is because you want MSDTC to have started prior to SQL Server starting. The problem now is the MSDTC log file is normally (but not always) stored on the cluster quorum drive. You'll need to change this in order for the MSDTC service to start.
Begin by searching through the registry for "MSDtc". You should find an entry under HKCR\CID\"some large CLSID"\CustomProperties\Log\Path. You'll want to change the path from Q:\ to another location.
All that is left now is to cross your fingers and start both the Distributed Transaction Service and the SQL Server Service. Viola'!
No comments:
Post a Comment