It has been a challenge to maintain files, documents along with the records in the database and gradually increasing the need of digitizing the data leads to the need for a more manageable system. Once a photographer asked me for a system that can manage all his customer data and the associated video clips, photos, etc. that go with each customer. Also he needed to maintain data for his associates and wanted a system that would be very efficient system to maintain and, more importantly, would allow the data to be easily backed up.
Much of the data that is created by the photographer above is unstructured data, such as text documents, images, and videos. This unstructured data is often stored outside the database, separate from its customer record which is structured data. Due to this separation it can lead to data management complexities in areas such as transactional consistency and database backups. Transactional consistency means if record gets updated, all parts of the record are updated. Backup for files and the database need to be done separately OR some external application has to manage the backup of both the storage systems. Well you might think if we can use the data type BOLB of SQL SERVER which allows us to store data upto 2 GB. But the problem with this is that file streaming becomes slow and performance of the database can be affected very badly.
SQL Server 2008 introduces a new data type: FILESTREAM. FILESTREAM allows large binary data (Documents, images, videos etc) to be stored directly in the Windows file system. This binary data remains an integral part of the database and maintains transactional consistency. FILESTREAM enables the storage of large binary data, traditionally managed by the database, to be stored outside the database as individual files that can be accessed using an NTFS streaming API. Using the NTFS streaming APIs allows efficient performance of common file operations while providing all of the rich database services, including security and backup.
What is FILESTREAM?
FILESTREAM is a new datatype in SQL SERVER 2008. To use FILESTREAM, a database needs to contain a FILESTREAM filegroup and a table which contains a varbinary(max) column with the FILESTREAM attribute set. This causes the Database Engine to store all data for that column in the file system, but not in the database file. A FILESTREAM filegroup is a special folder that contains file system directories known as data containers. These data containers are the interface between Database Engine storage and file system storage through which files in these data containers are maintained by Database Engine.
What FILESTREAM does?
By creating a FILESTREAM filegroup and setting a FILESTREAM attribute on the column of a table, a data container is created which will take care of DML statements.
FILESTREAM will use Windows API for streaming the files so that files can be accessed faster. Also instead of using SQL SERVER cache it will use Windows cache for caching the files accessed.
When you use FILESTREAM storage, consider the following:
- When a table contains a FILESTREAM column, each row must have a unique row ID.
- FILESTREAM data containers cannot be nested.
- When you are using failover clustering, the FILESTREAM filegroups must be on shared disk resources.
- FILESTREAM filegroups can be on compressed volumes.
How to use FILESTREAM
Step 1) Enabling FILESTREAM datatype
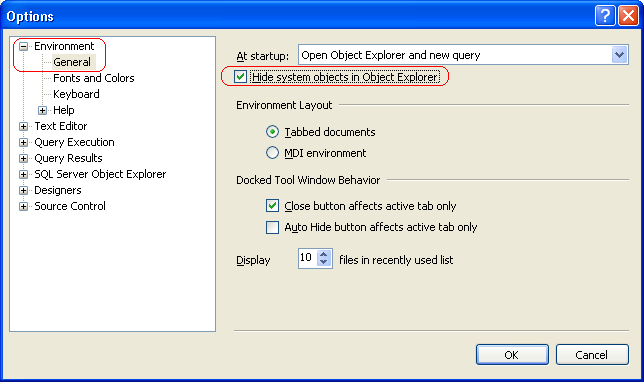
Before using FILESTREAM we need to enable it as FILESTREAM is by default disabled in SQL SERVER 2008. Enabling the instance for FILESTREAM is done by using the system store procedure “sp_FILESTREAM_configure”. The syntax is given as below:
USE MASTER
GO
EXEC sp_FILESTREAM_configure @enable_level = 3
There are various enable levels:
0 – Disable FILESTREAM
1 – Allow T-SQL only to access files
2 – Allow T-SQL as well File system access Locally
3 – Allow T-SQL as well File system access Locally as well as remotely
OR
Same thing can be done by setting the property of FILESTREAM
i.e. Configurable level = Transact-SQL and file system
Fig 1: Configure FILESTREAM
STEP 2) Creating File Group
Now let us create a filegroup. As discussed earlier Filegroup is like a folder which acts as an interface between Windows file system and SQL server.
USE MASTER
GO
CREATE DATABASE TEST_DB ON PRIMARY
( NAME = TEST_DB_data,
FILENAME = N’C:\ TEST_DB_data.mdf’),
FILEGROUP FG_1
( NAME = TEST_DB_REGULAR,
FILENAME = N’C:\ TEST_DB_data_1.ndf’),
FILEGROUP FG_2 CONTAINS FILESTREAM
( NAME = FS_FILESTREAM,
FILENAME = N’C:\TEST_FS’)
LOG ON
( NAME = FS_LOG,
FILENAME = N’C:\TEST_FS_log.ldf’);
GO
The statement below means that a FileGroup of type FILESTREAM will be created i.e. a data container named “TEST_FS” is created, which will act as an interface between Database Engine and Windows file system. The Database Engine can manage the files through this folder. It is necessary to specify the CONTAINS FILEGROUP clause for least one filegroup.
FILEGROUP FG_2 CONTAINS FILESTREAM
Note:
• The only difference in the statement above compared to a normal CREATE DATABASE statement is the filegroup creation for FILESTREAM objects.
• There should not be any folder by the name TEST_FS as it will be created by SQL SERVER and permission will be granted. If the database is deleted then SQL SERVER will delete the related files and folders.
• Please note that if you try to create this database by specifying a path for the FILESTREAM files that is not on NTFS, you will get the error message: “The path specified by ‘d:\TEST_FS’ cannot be used for FILESTREAM files because it is not on NTFS.”
Below is the figure that shows the folder that is created after execution of above DDL statement
Fig 2: Special Filegroup folder created.
For the FILESTREAM filegroup, the FILENAME refers to the path and not to the actual file name. It creates that particular folder - from the example above, it created the C:\TEST_FS folder on the filesystem. And that folder now contains a FILESTREAM.hdr file and also a folder $FSLOG folder.
Important Note: The FILESTREAM.hdr file is an important system file. It contains FILESTREAM header information. Do not remove or modify this file.
Adding FILESTREAM filegroup to existing database
If you already have a database, you can add a FILESTREAM filegroup to it using ALTER DATABASE command.
ALTER DATABASE [TEST_DB]
ADD FILEGROUP FG_2 CONTAINS FILESTREAM;
ALTER DATABASE [TEST_DB]
ADD FILE
(NAME = FS_FILESTREAM,FILENAME = N' C:\TEST_FS’
) TO FILEGROUP FG_2;
Step 3) Creating a Table
Once the database is ready we need a table having a column of Varbinary(max) with FILESTREAM attribute where the data will be stored. Let us create a table and add data into it.
USE TEST_DB
GO
CREATE TABLE FILETABLE
(
ID INT IDENTITY,
GUID UNIQUEIDENTIFIER ROWGUIDCOL NOTNULL UNIQUE,
DATA VARBINARY(MAX) FILESTREAM
);
The table definition needs a ROWGUIDCOL column - this is required by FILESTREAM. The actual data is stored in the 3rd column DATA. Any data manipulation in this column will update the file stored in the Windows system.
INSERT INTO FILETABLE (GUID, DATA) VALUES (NEWID(),NULL);
INSERT INTO FILETABLE (GUID, DATA) VALUES (NEWID(),CAST(‘TEST DATA’ AS VARBINARY(MAX)));
Note: File will not be created for the data value NULL.
Execute select query on the table - FILETABLE, and you get the following output.
ID GUID DATA
———– ——————————————————————— ————————–
1 78909DBF-7B26-4CA9-A840-4D45930F7523 NULL
2 0B0F5833-1997-4C9C-A9A7-F2536D68CFED 0×4D592044554D4D592054455354
As you can see on the file system, additional folders have been created under TEST_FS folder. The filename will be the GUID id. For eg. If you see the second record, the filename will be 0B0F5833-1997-4C9C-A9A7-F2536D68CFED and in the DATA column the contents of file are stored.
When to use FILESTREAM?
When applications need to store large files i.e. larger than 1 MB and also don’t want to affect database performance in reading the data, the use of FILESTREAM will provide a better solution. Also one can use this for developing applications that use a middle tier for application logic.
For smaller files, still one can safely store in columns with datatype varbinary(max) BLOBs in the database which would provide better streaming performance for small files.
Advantages
FILESTREAM enables the database to store un-structured (files, documents, images, videos etc) data on the file systems and still use the SQL SERVER Engine.
It uses Windows API’s for streaming the files.
When manipulating files, instead of using the SQL server cache, it uses Windows system cache.
SQL Server backup and recovery models support these files also along with the database. Only a single backup command is issued to back up the database and the FILESTREAM data.
All insert, update, delete, search queries will also work for this unstructured data.
FILESTREAM data is secured by granting permissions at the table or column level, similar to the manner in which any other data is secured. Only if you have permissions to the FILESTREAM column in a table, you can access its associated files.
In SQL Server, FILESTREAM data is secured just like other data is secured: by granting permissions at the table or column levels. If a user has permission to the FILESTREAM column in a table, the user can open the associated files.
Disadvantages
FILESTREAM does not currently support in-place updates. Therefore an update to a column with the FILESTREAM attribute is implemented by creating a new zero-byte file, which then has the entire new data value written to it. When the update is committed, the file pointer is then changed to point to the new file, leaving the old file to be deleted at garbage collection time. This happens at a checkpoint for simple recovery, and at a backup or log backup.
Limitations
Database mirroring cannot be configured on databases with FILESTEAM data.
Database snapshots are not supported for FILESTEAM data.
Native encryption is not possible by SQL SERVER for FILESTREAM data.
Conclusion
This article has explained about the new FILESTREAM datatype of SQL SERVER 2008 which provides easy way to maintain unstructured data along with the structured data as it uses Windows API to store files and manages the data into SQL SERVER database. As explained in the article FILESTREAM is easy to understand and implement in applications.